科研论文怎么写:从选题到投稿的全流程拆解
选题:如何找到既前沿又可行的研究切口?
很多研究生卡在之一步。自问:我能否在三个月内完成?答案往往取决于“数据可得性+ *** 成熟度”。一个实用技巧是:先锁定领域内近三年高被引综述,画出知识图谱,寻找尚未被系统回答的灰色地带。
结构:IMRaD之外的隐藏模块
- Graphical Abstract:让编辑五秒钟看懂你的创新点。
- Highlights:三到五条,每条≤85字符,用动词开头。
- Data Availability Statement:越来越多SCI期刊强制要求。
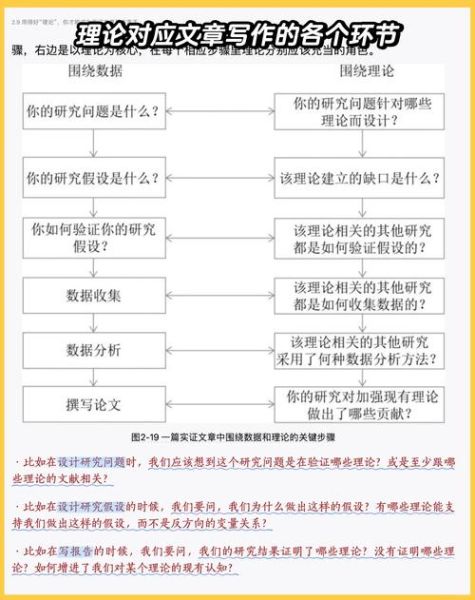
写作顺序:为什么先写Results再写Introduction?
因为结果决定故事线。把图和表排成逻辑链后,你会惊讶地发现:Introduction里需要铺垫的文献其实只有原先设想的一半。
语言:非母语者如何三天内提升可读性?
- 用Grammarly做之一轮语法筛查。
- 把文章贴进Writefull,对比千万级语料库。
- 最后人工替换所有“very”级别的弱形容词。
科研数据分析 *** 有哪些:从描述到因果的阶梯
之一步:描述性统计常被忽视的黄金指标
除了均值±标准差,中位数、四分位距、偏度、峰度能帮你快速发现异常分布。自问:数据是否正态?若偏度>2或峰度>7,后续参数检验可能失效。
第二步:推断统计如何选对检验?
| 数据类型 | 独立样本 | 配对样本 |
|---|
| 连续正态 | 独立样本t检验 | 配对t检验 |
| 连续非正态 | Mann-Whitney U | Wilcoxon符号秩 |
| 分类 | 卡方检验 | McNemar检验 |
第三步:高维数据降维的三种武器
- PCA:更大化方差,适合共线性强的光谱数据。
- t-SNE:保持局部结构,单细胞测序可视化首选。
- UMAP:兼顾全局与局部,计算速度比t-SNE快十倍。
第四步:因果推断超越“相关”的四种设计
观察性研究也能逼近因果,关键是控制混杂。
- 倾向得分匹配(P *** ):把混杂变量压缩成一维得分。
- 双重差分(DiD):政策评估常用,需满足平行趋势。
- 工具变量(IV):寻找只通过暴露影响结局的外生变量。
- 断点回归(RDD):利用政策阈值创造局部随机。
常见坑:90%新手在统计上栽的跟头
p值操纵:HARKing与p-hacking的区别
HARKing是事后把假设改成与数据相符,p-hacking是多次检验不报校正。预注册+Bonferroni校正能免疫。
样本量:G*Power算出的n为何常被低估?
软件默认效应量来自文献,但发表偏倚会夸大真实效应。保守做法是:把文献中的效应量减半再算。
缺失数据:删除还是插补?
如果缺失>5%,多重插补(MICE)优于单一均值填补。记得在附录报告插补前后的基线对比。
工具箱:提升效率的七款开源神器
- JASP:图形界面做贝叶斯分析,拖拽即可。
- R brms包:用lme4语法跑贝叶斯多层模型。
- Python stat *** odels:一行代码输出回归诊断图。
- Jamovi:SPSS平替,插件市场可装SEM模块。
- Orange:可视化编程,机器学习零代码。
- GitHub Actions:自动化生成论文图表,每次push即更新。
- Obsidian+Zotero:双向链接文献笔记,告别手动整理。
审稿人视角:他们到底在挑剔什么?
一位Nature子刊审稿人透露:之一眼先看图表是否自明(stand-alone),第二眼扫描 *** 部分是否可复现。所以,原始数据和代码链接放在cover letter里主动提供,能显著提高送审通过率。





暂时没有评论,来抢沙发吧~